Origify
Overview
Origify is a plagiarism detection tool built to maintain academic integrity in state education. The goal is to create a reliable system that identifies plagiarism in exam papers, ensuring every assessment remains authentic, transparent, and of the highest quality. By addressing academic dishonesty, Origify fosters a learning environment rooted in honesty, openness, and excellence.
Motives
- Authenticity, transparency, and quality in education
- Personal experience with the education system
Objective
- Promoting fairness and integrity in state education
Architecture
Data Processing
-
Document Text Preprocessing:
- Tokenization: Breaking text into individual tokens (words, punctuation, etc.) using
nltk.word_tokenize. - Stop Word Removal: Filtering out common words (e.g., "the", "a", "is") using NLTK’s
stopwordscorpus. - Stemming/Lemmatization: Reducing words to their base form using
PorterStemmerfrom NLTK.
- Tokenization: Breaking text into individual tokens (words, punctuation, etc.) using
-
Document Vectorization:
- TF-IDF (Term Frequency-Inverse Document Frequency): Converts text into numerical vectors that represent word importance across documents using
sklearn.feature_extraction.text.TfidfVectorizer.
Formula:
-
Term Frequency:
-
Inverse Document Frequency:
Where:- ( N ) is the total number of documents in the corpus.
- ( df(t,D) ) is the number of documents containing term ( t ) in the corpus ( D ).
-
TF-IDF Score:
A higher TF-IDF score indicates the term is more relevant to the document compared to the entire corpus.
- TF-IDF (Term Frequency-Inverse Document Frequency): Converts text into numerical vectors that represent word importance across documents using
-
Similarity Calculation:
- Cosine Similarity: Measures the similarity between TF-IDF vectors of the query document and existing documents using
sklearn.metrics.pairwise.cosine_similarity.
- Cosine Similarity: Measures the similarity between TF-IDF vectors of the query document and existing documents using
TODOs
- Logo
- UI & UX design
- Read about TF-IDF
- Save & Load Model
- Convert to Text
- Image to text (OCR)
- PDF to text
- Data scraping
- Ency
- Degrees
- CEM
- BEM
- BAC
- Dzexams (this was easy)
- Setup a sub-process to clean duplicated data from Ency & Dzexams
- Plain-Text Extraction
- Extract and save texts
- Stream text extraction to preprocessing & vectorization
- Preprocess data
- Save preprocessed text
- Vectorize data using TF-IDF
- Setup database
- Setup FastAPI
/compareendpoint authentication - Implement manual exam data submission via
/upload(maybe)- Check if uploaded exams already exist
- Setup an HTTP endpoint for running the data mining process (admin)
- Wait-listing system
- Payment Gateway Integration
- Stripe
- CIB/EDAHABIA
Features
- Users select the subject of the exam to optimize resource usage
- Shareable interactive links/documents/badges (inspired by Spotify's shareable images)
- Teacher scoring system (users enter the exam provider’s information)
Developer Tech Stack
Frontend
- React Native
- Logsnag - Event tracking
- Sentry - Performance monitoring & error tracking
- React Native Document Scanner - Camera vision
- Lucide - Icons & fonts
Backend
- Python
- HTTPX
- selectolax
- Playwright
- FastAPI
- sklearn
- nltk
- Betterstack
Data Sources
Design Prototypes
Wireframe
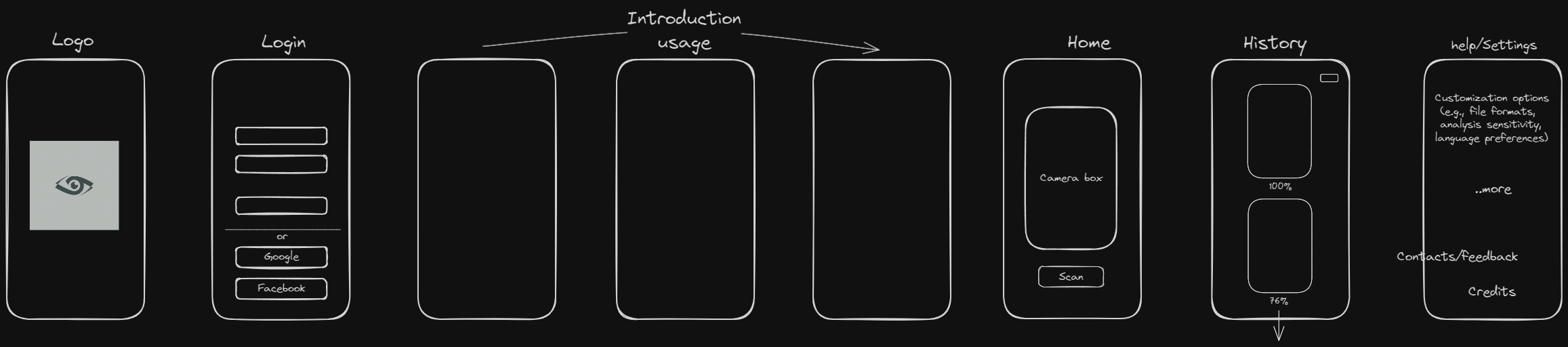
Mobile User Flow

Marketing
- Social Media - Origify Beta Short Form Ad
- TikTok
- Facebook Groups (education-related)
- Public Posters
- Direct messages to students & teachers
- Email outreach (inspired by Arc Browser’s copywriting)
Monetization
- Limited requests per week, with a pay-to-use credits system
Papers
- A research paper documenting the problem, solution, and methodology (inspired research paper)
- An analysis of how the availability of educational exam papers online reflects the decline of the Tamazight language (TODO: replace "decline" with a more appropriate term)